8. Actor-Critic 算法
纯策略梯度算法(如 REINFORCE)虽然解决了连续动作空间和随机策略的问题,但高方差和低采样效率限制了其在复杂任务中的表现。
具身智能视角:Actor-Critic 是 PPO、SAC、TD3 等主流算法的共同基础框架。理解 Actor-Critic 的原理(特别是 GAE)对于调试和改进具身智能中的 RL 训练至关重要。
8.1 纯策略梯度的缺点
策略梯度算法的目标函数:
其中
8.2 Actor-Critic 原理
Actor-Critic 将值估计交给独立的 Critic 网络,而 Actor 专注于策略优化:
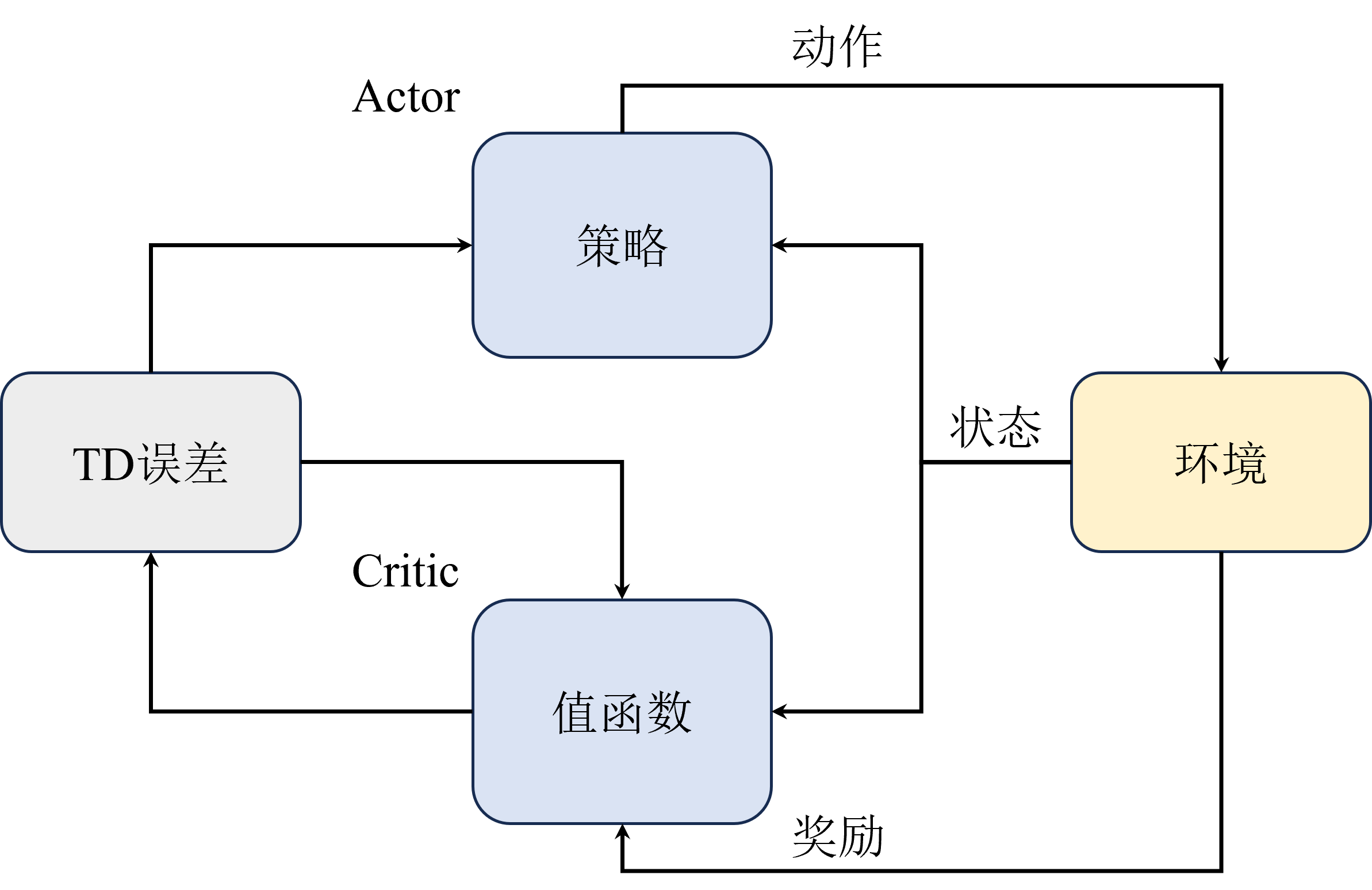
Actor-Critic 更多是一种框架,不同算法的实现可能不同。对于 Critic 部分,可以使用状态价值函数
Value Actor-Critic(使用状态价值):
Critic 通过时序差分(TD)方法更新参数:
8.3 A2C 算法
为了进一步降低方差,引入优势函数(Advantage Function):
优势函数衡量了在给定状态下选择特定动作相对于平均水平的优势。通过减去基线
A2C 的目标函数:
8.4 A3C 算法
A3C(Asynchronous Advantage Actor-Critic)通过多个并行智能体同时与环境交互,每个智能体将参数异步更新到全局网络:
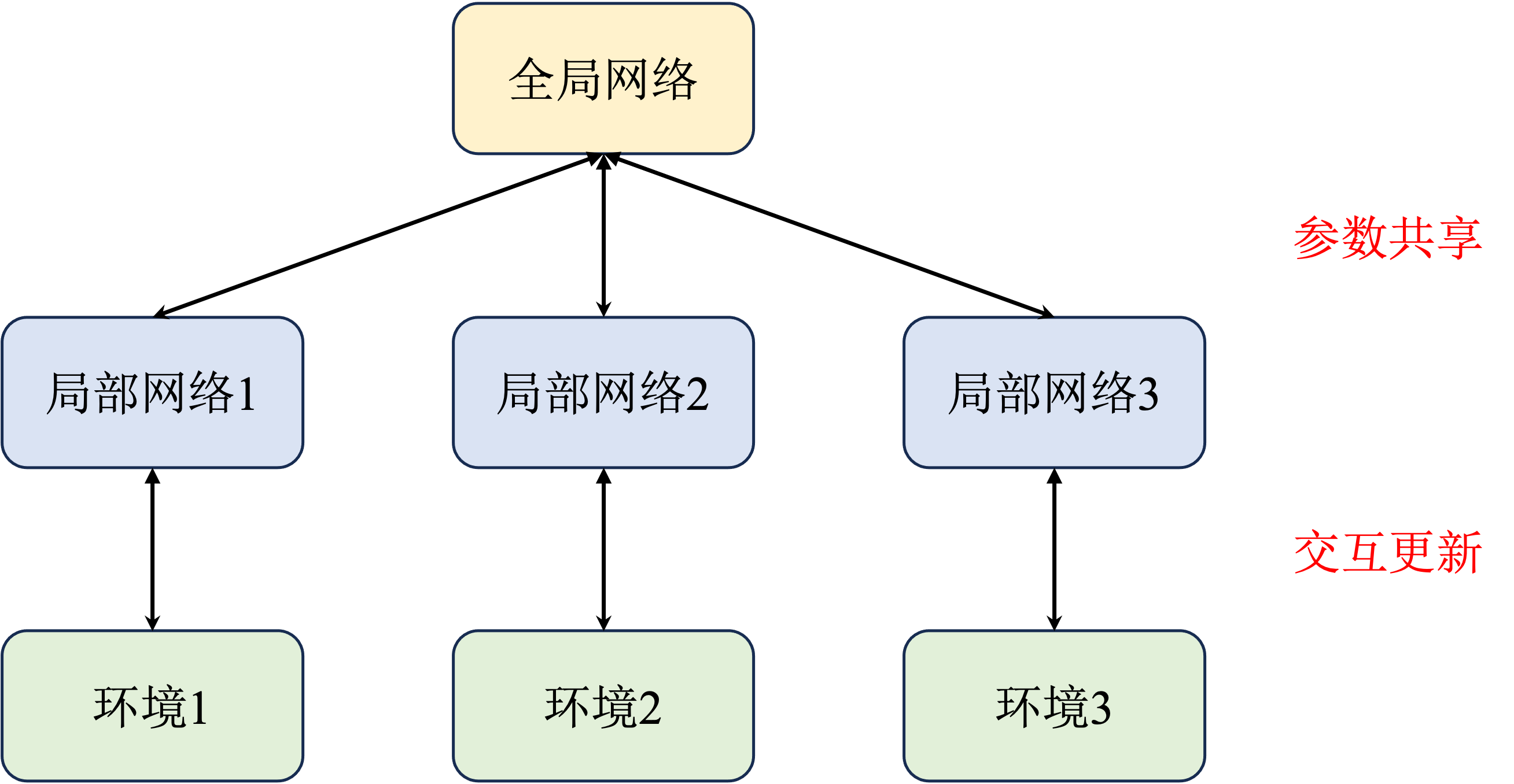
多进程训练的思路也广泛应用于其他算法(如 PPO 在 Isaac Gym 中使用数千个并行环境),能显著提高训练效率和探索能力。
8.5 广义优势估计(GAE)
优势函数的估计方式直接影响训练效果。常见的估计方式有:
单步 TD 估计(方差小、偏差大):
蒙特卡洛估计(无偏、方差大):
广义优势估计(GAE) 通过参数
其中
GAE 有一个高效的递推形式,非常适合实现:
- 当
时,退化为单步 TD 误差 - 当
时,退化为蒙特卡洛估计 - 常用
,在偏差和方差之间取得平衡
8.5.1 GAE 的 PyTorch 实现
import torch
def compute_gae(rewards, values, dones, gamma=0.99, lam=0.95):
"""
计算 Generalized Advantage Estimation (GAE)
rewards: shape = [T],每一步的即时奖励
values: shape = [T+1],值函数 V(s_t)
dones: shape = [T],是否为终止状态
"""
T = len(rewards)
advantages = torch.zeros(T, dtype=torch.float32)
last_adv = 0.0
for t in reversed(range(T)):
if dones[t]:
next_non_terminal = 0.0
next_value = 0.0
else:
next_non_terminal = 1.0
next_value = values[t + 1]
delta = rewards[t] + gamma * next_value * next_non_terminal - values[t]
advantages[t] = delta + gamma * lam * next_non_terminal * last_adv
last_adv = advantages[t]
returns = advantages + values[:-1]
return advantages, returns
8.6 小结
Actor-Critic 框架是现代 RL 算法的基础:
- Actor 负责策略优化,Critic 负责价值评估
- 优势函数通过减去基线降低方差
- GAE 提供了偏差-方差权衡的灵活方式
- PPO = Actor-Critic + 重要性采样 + Clip 约束
- SAC = Actor-Critic + 最大熵 + 自动温度调节