3. 动态规划
动态规划是一种用于解决复杂问题的数学方法,广泛应用于计算机科学、经济学等领域,其核心思想是将问题分解为更小的子问题,并存储这些子问题的解决方案,以避免重复计算,从而提高效率。
在强化学习中,动态规划被用于求解值函数和最优策略,核心概念是贝尔曼方程,它描述了状态价值函数和动作价值函数的递归关系。
具身智能视角:动态规划是理解强化学习算法的理论基石。虽然在实际机器人控制中很少直接使用(因为需要完整的环境模型),但策略迭代和价值迭代的思想贯穿了后续所有 RL 算法——从 DQN 的 Q 值更新到 PPO 的策略优化,都能看到贝尔曼方程的影子。
基于动态规划的强化学习算法主要包括策略迭代和价值迭代等,这些算法依赖于对环境的完全了解,即需要知道状态转移概率和奖励函数,即属于有模型的方法。这两种算法虽然现在很少直接应用于实际问题,但它们为理解更复杂的强化学习算法奠定了基础。
3.1 动态规划
动态规划(
动态规划能够解决的问题通常具备三个性质:重叠子问题(
动态规划通常采用自底向上的方法,通过迭代地解决子问题,最终得到原始问题的解决方案。常见的动态规划算法包括斐波那契数列、背包问题和路径规划问题等。
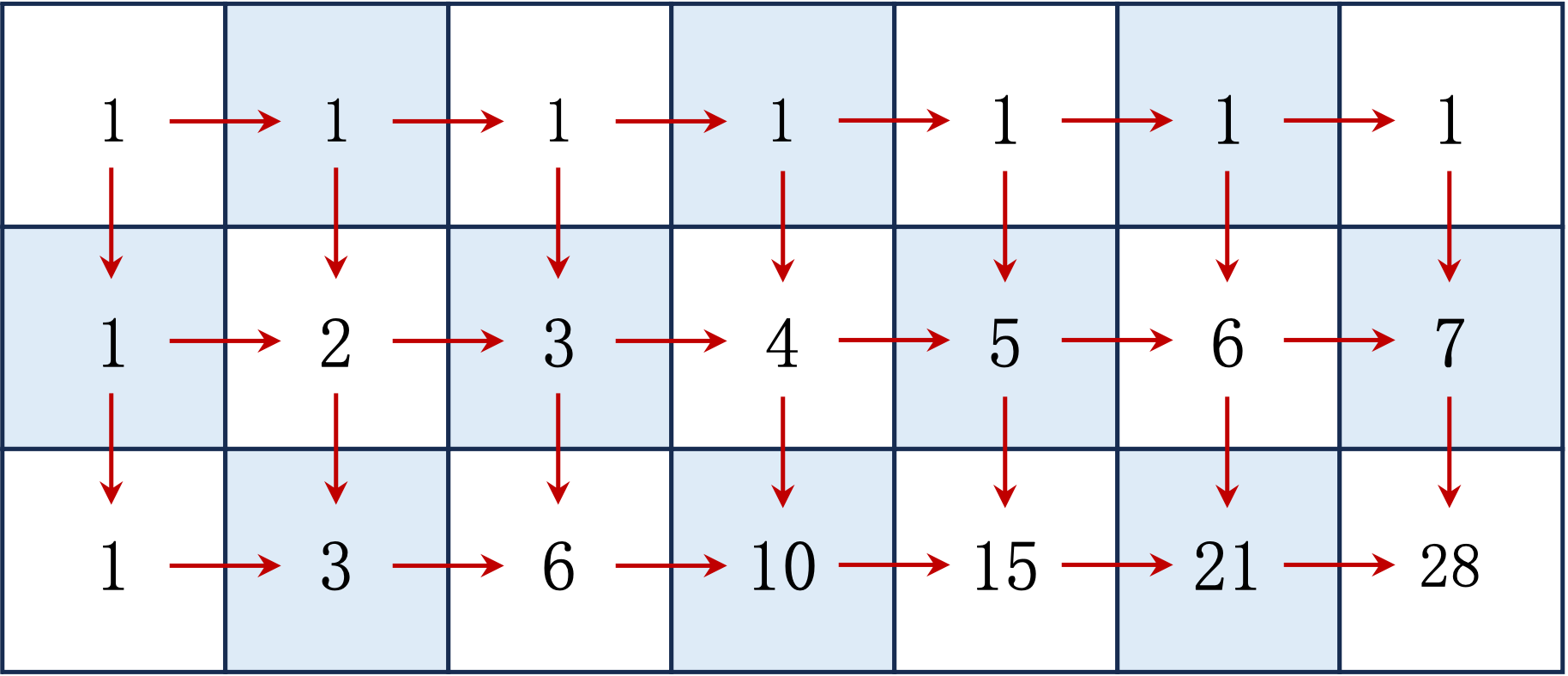
为帮助理解动态规划的思想,这里以一个路径规划问题为例进行说明。如图 1 所示,在一个
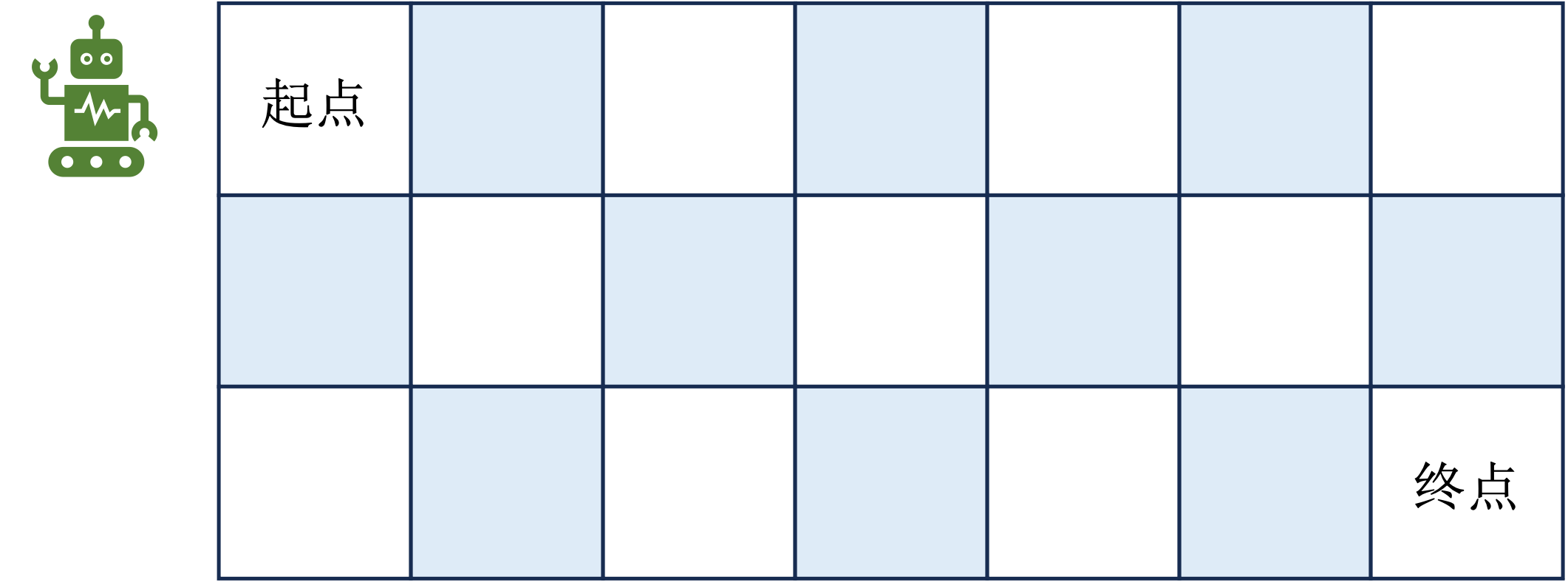
使用动态规划的方法来解决这个问题的话,主要包含几个步骤:确定状态,写出状态转移方程和寻找边界条件。
首先可以将状态定义为
即走到当前位置
然后再考虑一些边界条件。上面的状态转移方程只适用于内部位置,即
代入边界条件后,状态转移方程可以完善如式
实现如代码 1 所示。
def solve(m,n):
# 初始化边界条件
f = [[1] * n] + [[1] + [0] * (n - 1) for _ in range(m - 1)]
# 状态转移
for i in range(1, m):
for j in range(1, n):
f[i][j] = f[i - 1][j] + f[i][j - 1]
return f[m - 1][n - 1]
输入
在强化学习中,基于动态规划的算法主要有两种,一是策略迭代(
价值迭代则是将策略评估和策略改进合并在一起进行。这两种算法都依赖于对环境的完全了解,即需要知道状态转移概率和奖励函数,因此在实际应用中受到了一定的限制。然而,它们为理解更复杂的强化学习算法奠定了基础。
3.2 贝尔曼方程
3.2.1 状态价值形式
类比于回报公式
其中
贝尔曼方程相当于动态规划中的状态转移方程,将整体期望拆分"当前+未来"两部分递归地计算。它也进一步表示了当智能体在环境中处于某个状态
3.2.2 动作价值形式
类似地,贝尔曼方程的动作价值形式如式
3.2.3 贝尔曼最优方程
在一个马尔可夫决策过程中,我们可以找到一个最优策略
这个公式就是贝尔曼最优方程(Bellman optimality equation),它对于后面要讲的策略迭代算法具有一定的指导意义。同理,对应的动作价值函数形式如式
3.3 策略迭代
策略迭代算法是一种用于求解最优策略的动态规划方法。它通过交替进行策略评估和策略改进两个步骤,逐步逼近最优策略。
在策略评估步骤中,固定当前策略
如图 3 所示,(a)描述了上面所说的策略评估和改进持续迭代的过程,(b)则描述了在交替迭代过程中策略
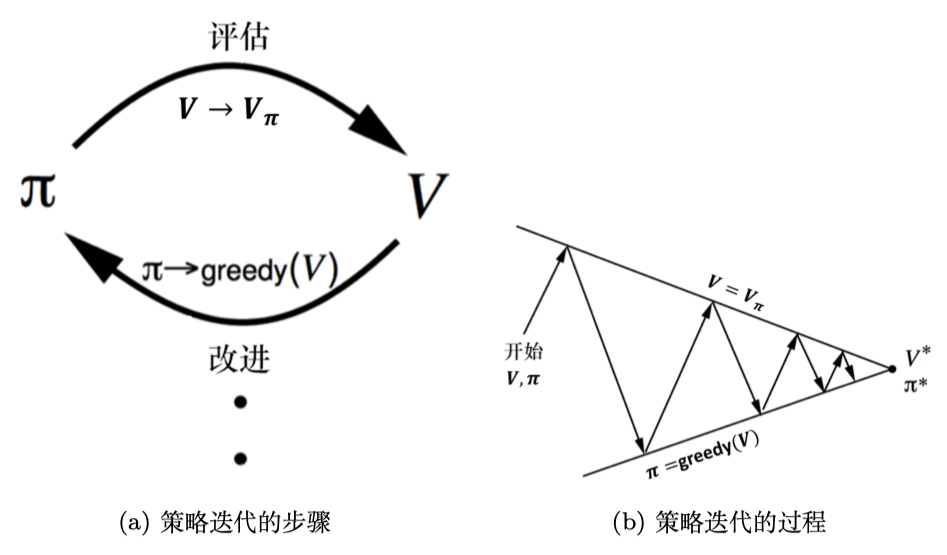
策略迭代的算法流程如图 4 所示。

在这个过程中,每一步需要遍历所有状态和动作,因此计算复杂度较高。然而,由于策略迭代能够有效地利用当前策略的信息来改进策略,通常需要的迭代次数会更少些。策略迭代就好像一个喜欢深思熟虑的人,每次都会花充分的时间来评估当前的策略,想通了再迈步改进。
3.4 价值迭代
价值迭代算法的核心思想是将策略评估和策略改进合并在一起进行。它通过直接更新状态价值函数
价值迭代的算法流程如图 5 所示。

在这个过程中,首先将所有的状态价值初始化,然后不停地对每个状态迭代,直到收敛到最优价值
如图 6 所示,策略迭代是不停地在
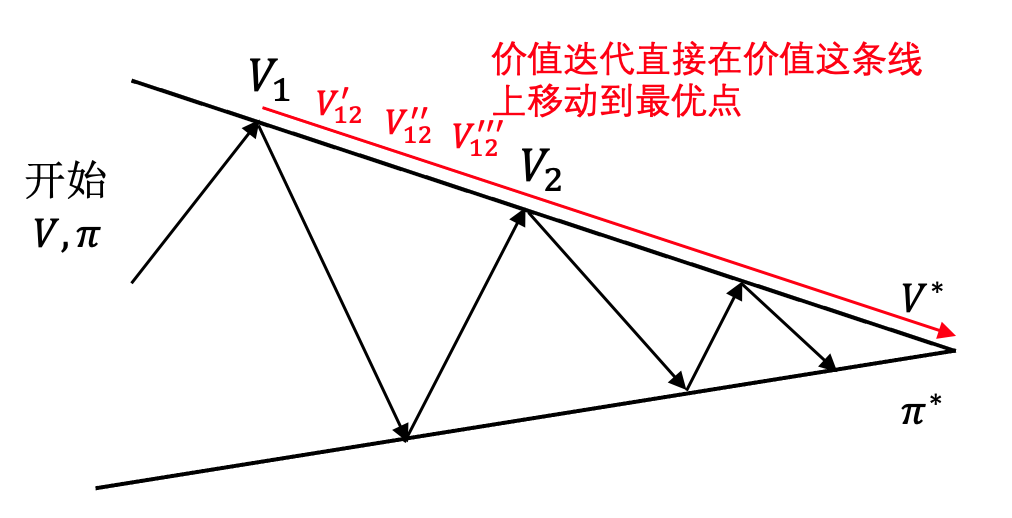
与策略迭代相比,价值迭代更像是一个急功近利的人,喜欢快速做出决策并迭代,而不是花时间去深思熟虑当前的策略再做改进。
换句话说,策略迭代每一步都需要花费较多时间去评估和改进策略,但通常需要的迭代次数较少;而价值迭代每一步计算量较小,但通常需要更多的迭代次数才能收敛到最优策略。如果环境模型简单,状态空间较小,策略迭代更加高效;而如果环境模型复杂,状态空间较大,价值迭代可能更适合。在现代实际应用中,我们几乎总是选择价值迭代作为首选思路,因为它每次迭代的计算量较小,更适合处理大规模问题。
3.5 思考
动态规划问题的主要性质有哪些?
动态规划主要性质包括最优化原理、无后效性和有重叠子问题,其中无后效性指的是某状态以后的过程不会影响以前的状态,这十分契合马尔可夫性质,因此动态规划问题可以看作是马尔可夫决策过程的一种特殊情况。
动态规划为什么通常采用自底向上的方法而不是自顶向下的方法?
动态规划通常采用自底向上的方法,因为这种方法可以避免重复计算子问题,从而提高效率。自底向上的方法通过迭代地解决子问题,逐步构建出原始问题的解决方案,而自顶向下的方法则可能会多次计算相同的子问题,导致计算量增加。此外,自底向上的方法更容易实现和理解,因为它直接从最简单的子问题开始,逐步扩展到更复杂的问题。
状态价值函数和动作价值函数之间的关系是什么?
一般来说,状态价值函数是动作价值函数在当前策略
策略迭代和价值迭代是有模型还是无模型的方法?
策略迭代和价值迭代都是有模型的方法,因为它们都需要知道环境的状态转移概率和奖励函数,以便进行状态价值函数和动作价值函数的计算和更新。
策略迭代和价值迭代哪个算法速度会更快?
策略迭代每一步需要花费较多时间去评估和改进策略,但通常需要的迭代次数较少;而价值迭代每一步计算量较小,但通常需要更多的迭代次数才能收敛到最优策略。因此,具体哪个算法速度更快取决于问题的具体情况。如果环境模型简单,状态空间较小,策略迭代可能更高效;而如果环境模型复杂,状态空间较大,价值迭代可能更适合。