2. 马尔可夫决策过程
马尔可夫决策过程(
具身智能视角:以机械臂抓取为例,状态
可以是关节角度 + 物体位姿,动作 是各关节的目标力矩,奖励 是抓取成功与否的信号。将这些要素明确后,就可以用 RL 算法来求解最优策略。
2.1 智能体与环境交互
如下图所示,智能体(
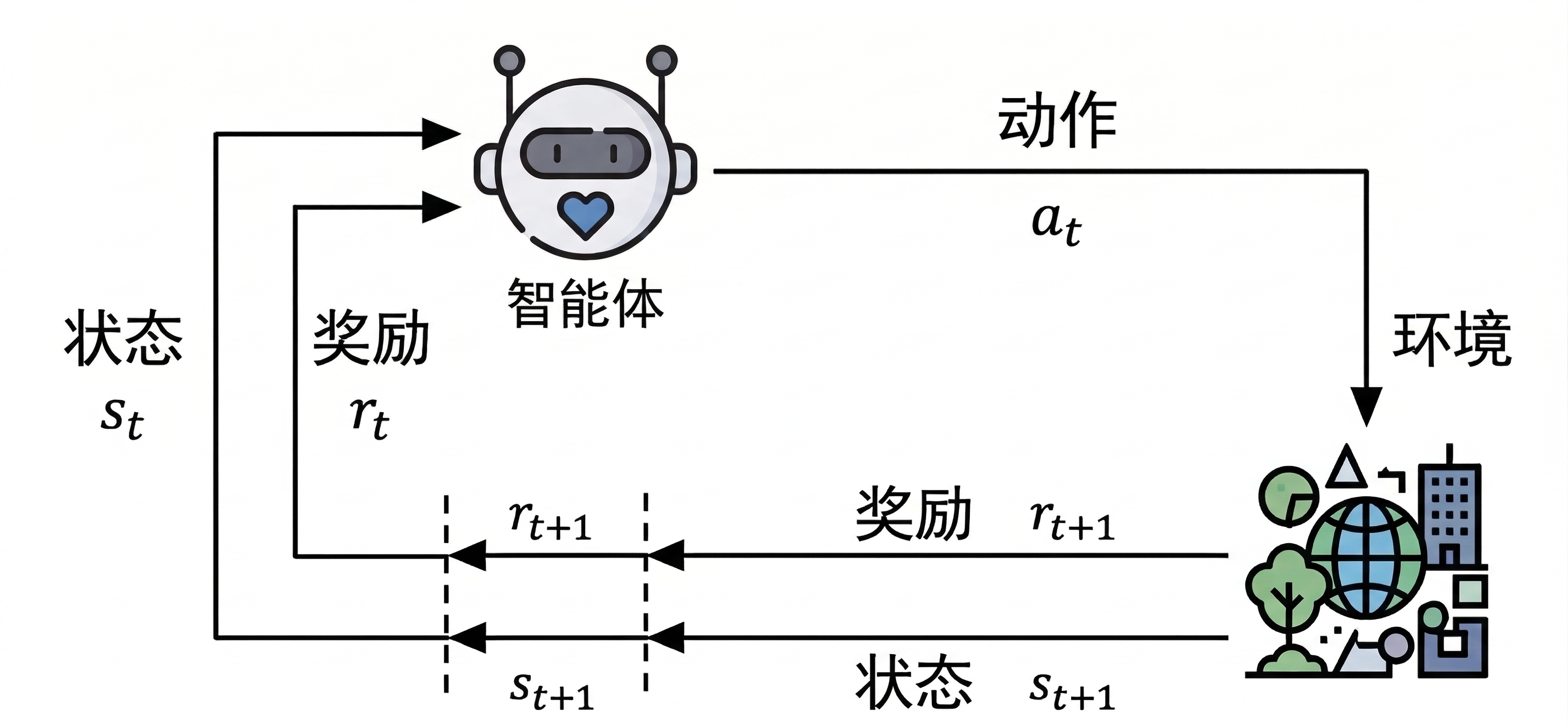
这个过程不断重复,形成一条轨迹:
完成一条完整的轨迹(从初始状态到终止状态)也称为一个回合(
如果要用强化学习来解决问题,首先需要将问题建模为马尔可夫决策过程,即明确状态空间、动作空间、状态转移概率和奖励函数等要素。通常用一个五元组来定义:
其中
2.2 马尔可夫性质
马尔可夫决策过程的核心假设是马尔可夫性质,即系统未来状态的概率分布只依赖于当前的状态和动作,而与过去的状态和动作无关:
在真实机器人场景中,严格满足马尔可夫性质的情况并不多见。例如在机器人导航中,当前的激光雷达扫描可能不足以完全描述环境状态(存在遮挡)。但大多情况下,可以通过适当的状态表示(如叠加历史帧)来近似满足马尔可夫性质,这样的过程叫做部分可观测马尔可夫决策过程(POMDP)。
2.3 状态转移矩阵
对于有限状态空间,可以用状态流向图表示状态之间的转移关系。如下图所示:
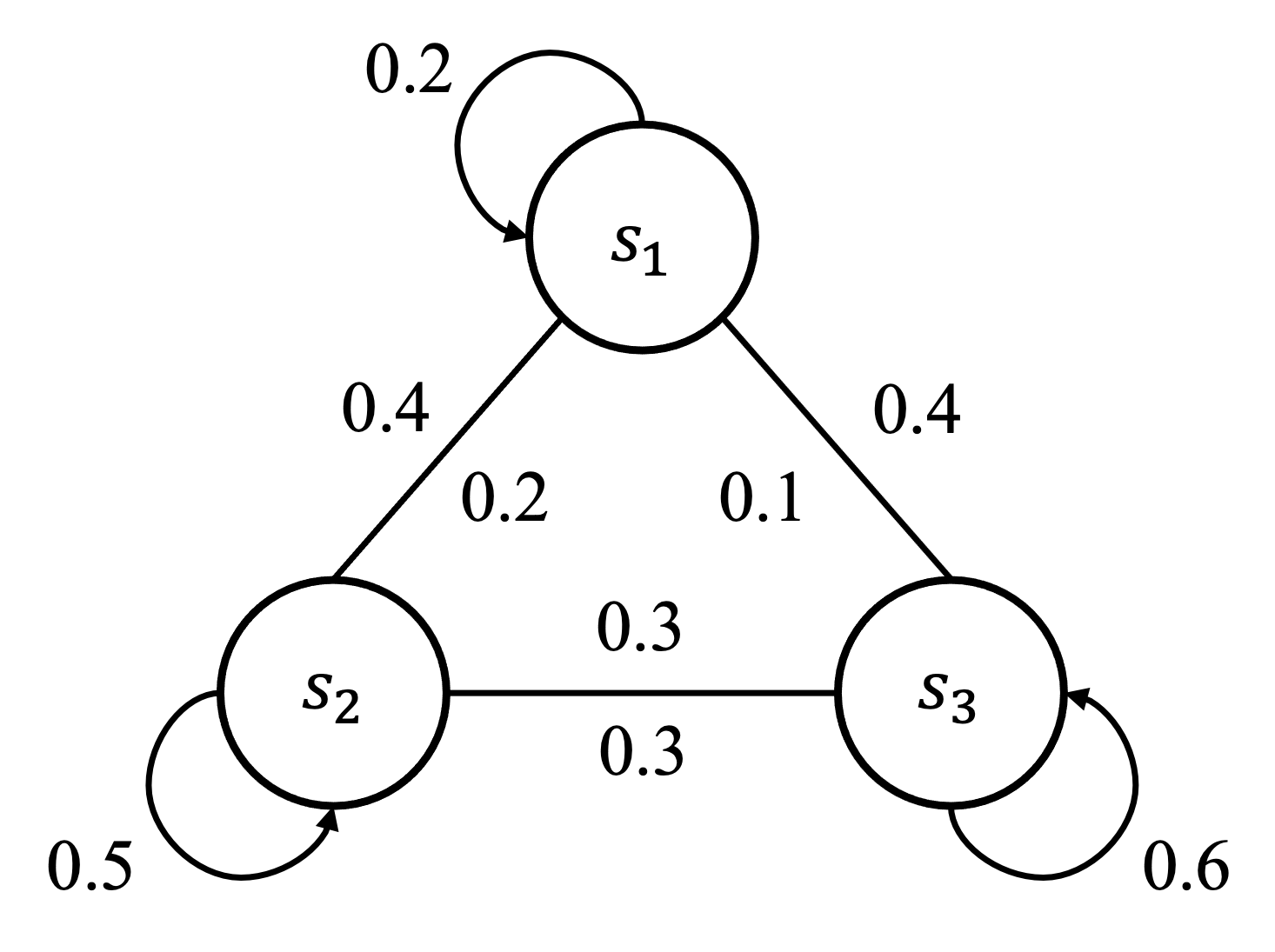
状态之间的切换概率可以用矩阵表示:
其中
2.4 目标与回报
智能体的目标是通过与环境的交互,学习一个最优策略,使得在每个状态下选择的动作能够最大化累积的奖励。这个累积的奖励称为回报(Return):
折扣因子
折扣因子可以用来衡量智能体对长期回报的关注度,称之为有效视界:
当
回报的递归定义:
2.5 策略与价值
2.5.1 策略
策略(
策略可以是确定性的(在每个状态下总是选择同一个动作)或随机性的(根据概率分布选择动作)。在具身智能中,随机性策略更为常用,因为它能提供更好的探索能力和鲁棒性。
2.5.2 状态价值
状态价值函数表示在给定状态下,按照策略
2.5.3 动作价值
动作价值函数表示在给定状态
2.5.4 状态价值与动作价值的关系
状态价值是对所有可能的动作价值的加权平均。状态价值反映了策略本身的好坏,动作价值则更具体地反映了在特定状态下选择某个动作的好坏。
2.6 有模型与无模型
- 有模型方法(Model-Based):利用环境模型(状态转移概率和奖励函数)来进行规划和决策,如动态规划。在仿真环境中,有时可以获得环境模型来加速学习。
- 无模型方法(Model-Free):不依赖于环境模型,通过与环境的直接交互来学习,如 PPO、SAC 等。在真实机器人场景中应用更广泛,因为真实环境的动力学模型通常难以精确获取。
2.7 预测与控制
- 预测:在给定策略下,评估该策略的好坏,即计算价值函数。
- 控制:寻找最优策略,使得累积回报最大化。
复杂问题中通常需要同时解决预测和控制问题,即在学习最优策略的过程中,同时评估当前策略的好坏(这正是 Actor-Critic 框架的思想)。