7. 策略梯度方法
基于策略梯度的方法是具身智能中最常用的 RL 方法家族(PPO、SAC 等都属于此类)。其核心思想是直接将策略参数化,然后通过梯度优化来改进策略。
具身智能视角:机器人控制通常涉及高维连续动作空间(如 30+ 自由度的人形机器人),策略梯度方法可以直接输出连续的关节力矩,无需对动作空间离散化,因此是具身智能的核心方法。
7.1 策略参数化
策略梯度方法首先将策略参数化,即直接将策略
目标函数表示为
实际中常转化为梯度下降法(最小化负值):
也就是说,只要能定义出目标函数
怎么定义关于策略的目标函数
7.2 基于轨迹推导
7.2.1 轨迹概率密度
智能体与环境交互产生轨迹:
为了计算轨迹产生的概率,我们可以先具体展开轨迹产生的路径。如下图所示,首先环境会从初始状态分布中采样出一个初始状态
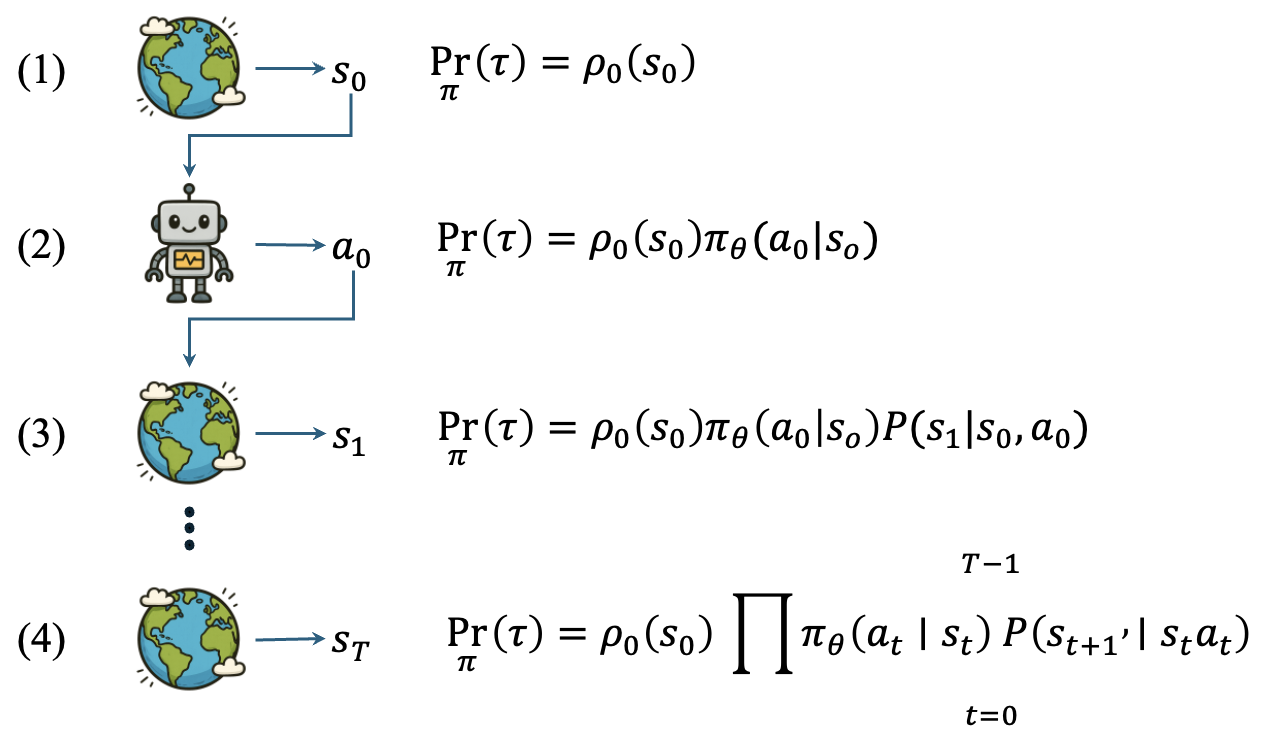
以此类推,可得完整轨迹的概率计算:
可以看出,轨迹概率确实可以写成关于策略
7.2.2 对数导数技巧
为了最大化目标函数
然而,轨迹概率密度
代入后可得:
由于环境的状态转移概率
最终得到基于轨迹的策略梯度表达式:
关键发现:策略梯度不依赖于环境的状态转移概率
7.3 占用测度推导
7.3.1 平稳分布
在引入平稳分布概念之前,先来看一个例子。假设有一个简单的马尔可夫过程,包含三个状态
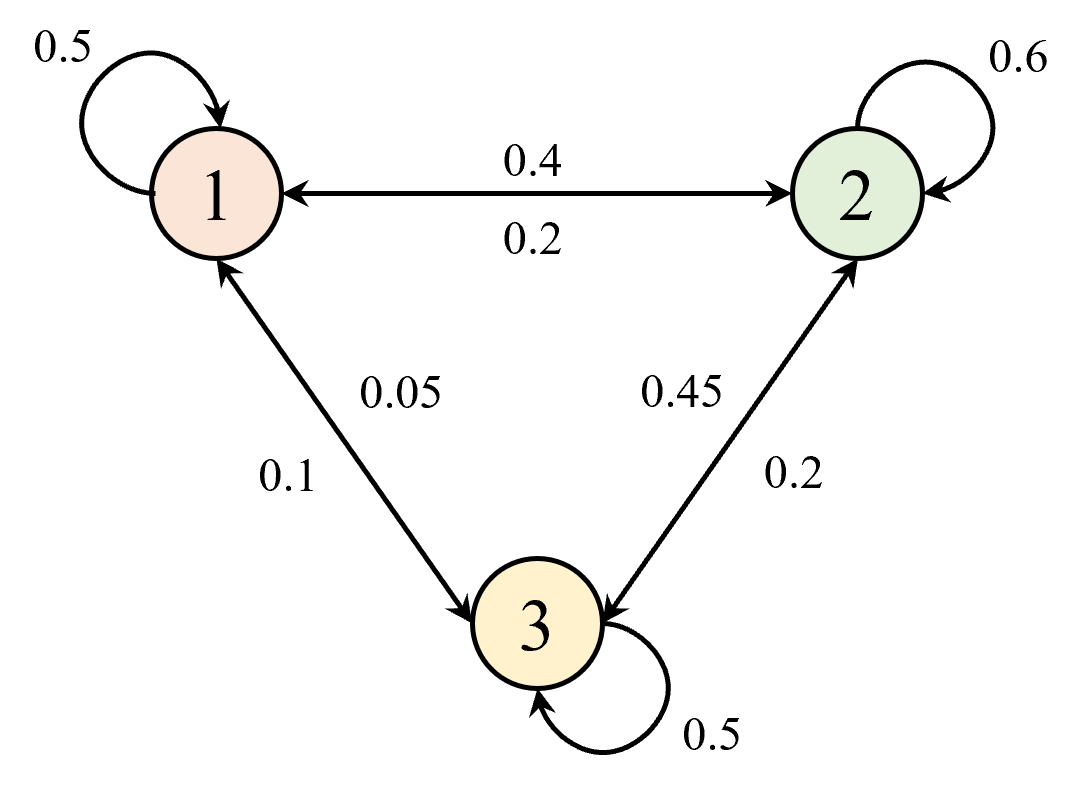
设初始状态分布为
import numpy as np
pi_0 = np.array([[0.15,0.62,0.23]])
P = np.array([[0.5,0.4,0.1],[0.2,0.6,0.2],[0.05,0.45,0.5]])
for i in range(1,10+1):
pi_0 = pi_0.dot(P)
print(f"第{i}次迭代后状态分布为:{np.around(pi_0,3)}")
运行结果:
第1次迭代后状态分布为:[[0.21 0.536 0.254]]
第2次迭代后状态分布为:[[0.225 0.52 0.255]]
...
第10次迭代后状态分布为:[[0.232 0.516 0.253]]
可以看出,经过多次迭代后,状态分布逐渐趋于稳定,并最终收敛到一个固定的分布,即
需要注意的是,平稳分布的存在需要马尔可夫过程是遍历(
7.3.2 目标函数梯度
由于经过多次迭代后状态访问分布会逐渐趋于平稳分布
对应的梯度推导(忽略平稳分布关于参数
这两种推导方式(基于轨迹和基于占用测度)实际上是等价的,区别在于一个从时间步
7.4 策略梯度通用表达式
在 GAE 论文中,提出了一种更为通用的策略梯度表达式:
其中
:整条轨迹的累计奖励 :动作 之后的累计奖励 :折扣回报,即 REINFORCE 算法形式 :引入基线函数 来减少方差 :动作价值函数 :优势函数 :时序差分误差(TD error)
其中
7.5 策略函数建模
7.5.1 离散动作空间:Categorical 分布
对于离散动作空间,使用 Softmax 函数将网络输出转化为概率分布:
其中
下面使用 NumPy 和 PyTorch 分别实现:
import numpy as np
def softmax(z):
z = np.array(z)
e = np.exp(z - np.max(z))
return e / e.sum()
logits = [2.0, 1.0, 0.1]
probs = softmax(logits)
action = np.random.choice(len(probs), p=probs)
log_prob = np.log(probs[action])
print(f"动作索引: {action}, 动作概率: {probs[action]:.3f}, log π(a|s): {log_prob:.3f}")
import torch
import torch.nn as nn
import torch.nn.functional as F
class PolicyNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(PolicyNetwork, self).__init__()
self.fc = nn.Linear(state_dim, action_dim)
def forward(self, x):
return F.softmax(self.fc(x), dim=-1)
state_dim, action_dim = 4, 3
policy_net = PolicyNetwork(state_dim, action_dim)
state = torch.FloatTensor([1.0, 0.5, -0.5, 2.0])
action_probs = policy_net(state)
# 从动作概率中采样动作
action_dist = torch.distributions.Categorical(action_probs)
action = action_dist.sample()
log_prob = action_dist.log_prob(action)
7.5.2 连续动作空间:高斯分布
对于连续动作空间(机器人控制的常见场景),使用高斯分布来参数化策略。
标量高斯分布(单维动作,如机器人推力大小):
其中均值
向量高斯分布(多维动作空间,如多关节机器人),使用多元高斯分布,每个维度独立:
对应的对数概率密度:
下面是高斯策略网络的 PyTorch 实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class GaussianPolicy(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc1 = nn.Linear(state_dim, 128)
self.fc_mu = nn.Linear(128, action_dim)
self.fc_logstd = nn.Linear(128, action_dim)
def forward(self, state):
x = F.relu(self.fc1(state))
mu = self.fc_mu(x)
log_std = self.fc_logstd(x).clamp(-20, 2) # 避免数值不稳定
std = log_std.exp()
return mu, std
def get_action(self, state):
mu, std = self.forward(state)
dist = torch.distributions.Normal(mu, std)
action = dist.sample() # 采样动作
log_prob = dist.log_prob(action).sum(dim=-1)
return action, log_prob
7.6 REINFORCE 算法
REINFORCE 算法是最基础的策略梯度算法,使用蒙特卡洛估计来计算回报。在 REINFORCE 算法中,通常使用回报
使用蒙特卡洛方法来估计梯度,即通过多次采样轨迹

REINFORCE 算法简单直观,但存在高方差和低采样效率的问题,因为它需要完整的轨迹来估计回报。这正是后续 Actor-Critic 算法要解决的问题。
7.7 小结
策略梯度方法为后续的高级算法(Actor-Critic、PPO、SAC)奠定了理论基础。核心要点:
- 策略参数化为可微的概率分布
- 通过基于轨迹概率密度和占用测度两种方式可以推导出等价的策略梯度表达式,且梯度计算不依赖环境模型
- 离散动作空间使用 Categorical 分布(Softmax),连续动作空间使用高斯分布
- 通用策略梯度表达式中的
选择不同形式,对应不同的算法(REINFORCE、Actor-Critic、PPO 等) - REINFORCE 的高方差问题推动了 Actor-Critic 框架的发展
7.8 思考
为什么使用 Softmax 函数来建模离散动作空间的策略?
主要考虑以下因素:(1) 该函数是可微分的,这是计算梯度的必要条件;(2) 可以确保概率为正数且所有动作的概率之和为 1,符合概率分布的要求;(3) 指数函数能够放大差距,让策略更倾向于"高分动作",但过度放大可能导致探索不足。
REINFORCE 算法是无偏的吗?
是的,因为它使用了蒙特卡洛方法来估计策略梯度,所得到的梯度估计是对真实梯度的无偏估计。然而,由于使用了采样方法,估计的方差可能较大。
如何改进 REINFORCE 算法以提高样本效率?
- 使用基线函数来减少梯度估计的方差
- 采用时间差分(TD)方法来替代蒙特卡洛估计
- 使用经验回放技术来重用过去的经验数据
- 结合价值函数近似方法,如 Actor-Critic 方法
基于价值和基于策略的算法各有什么优缺点?
基于价值的方法(如 DQN):简单稳定,但受限于离散动作空间。基于策略的方法(如 REINFORCE):直接优化策略,适用于连续动作空间,探索更高效,但高方差可能导致收敛较慢。实践中 Actor-Critic 算法结合了两者的优点。