5. 时序差分方法
时序差分方法结合了蒙特卡洛方法和动态规划的思想,允许在每个时间步进行更新,而不需要等待回合结束。
具身智能视角:时序差分方法是现代深度强化学习算法的核心更新机制。DQN 的 Q 值更新、DDPG/SAC 的 Critic 更新本质上都是 TD 学习。在机器人控制中,TD 方法的逐步更新特性使得智能体可以在与环境交互的同时实时学习,而无需等待完整回合结束。
5.1 时序差分估计
回顾蒙特卡洛估计的更新,如式
其中回报
尽管蒙特卡洛方法可以通过增量式更新来迭代预测状态价值函数
为了解决这个问题,时序差分(
其中,
当前估计与目标之间的差值则被称为时序差分误差(
这种使用当前估计来更新现有估计的方式被称为自举(
注意,实际应用中会考虑终止状态的特殊情况,由于终止状态没有下一个状态,因此在更新时需要单独处理,通常将终止状态的估计值设为
5.2 时序差分估计计算示例
回顾蒙特卡洛方法中讲到的
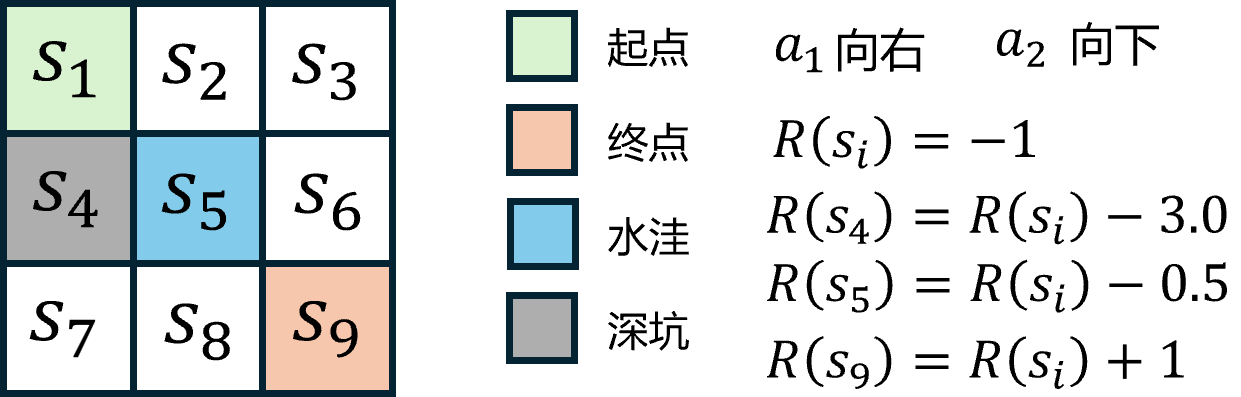
除了每走一步接收
用 Python 实现时序差分估计的代码并且对比蒙特卡洛估计的结果,如代码 1 所示。
import random
from collections import defaultdict
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
# ---------- 参数 ----------
gamma = 0.9
alpha = 0.1 # 学习率(可试 0.05~0.2)
episodes = 100000
states = [f"s{i}" for i in range(1, 10)]
terminal = "s9"
start = "s1"
coords = {
"s1": (0,0), "s2": (0,1), "s3": (0,2),
"s4": (1,0), "s5": (1,1), "s6": (1,2),
"s7": (2,0), "s8": (2,1), "s9": (2,2)
}
# ---------- 环境 ----------
def legal_actions(s):
r, c = coords[s]
acts = []
if c < 2: acts.append("right")
if r < 2: acts.append("down")
return acts
def step(s, a):
r, c = coords[s]
if a == "right": r2, c2 = r, c + 1
elif a == "down": r2, c2 = r + 1, c
s2 = [k for k, v in coords.items() if v == (r2, c2)][0]
reward = -1.0
if s2 == "s4": reward -= 3.0 # 深坑
if s2 == "s5": reward -= 0.5 # 水洼
if s2 == "s9": reward += 1.0 # 终点 +1 → 净0
done = (s2 == terminal)
return s2, reward, done
def policy(s):
acts = legal_actions(s)
return random.choice(acts)
def generate_episode():
episode = []
s = start
while True:
if s == terminal:
episode.append((s, None, 0))
break
a = policy(s)
s2, r, done = step(s, a)
episode.append((s, a, r))
s = s2
return episode
# ---------- First-Visit Monte Carlo ----------
def first_visit_mc(num_episodes=episodes, gamma=0.9):
V = defaultdict(float)
N = defaultdict(int)
for _ in range(num_episodes):
episode = generate_episode()
G = 0
visited = set()
for s, a, r in reversed(episode):
G = gamma * G + r
if s not in visited:
visited.add(s)
N[s] += 1
V[s] += (G - V[s]) / N[s]
return V
# ---------- TD(0) 预测 ----------
def td0_value_prediction(episodes=episodes, alpha=alpha, gamma=gamma, start="s1"):
V = defaultdict(float) # 初始全0
for _ in range(episodes):
s = start
while s != terminal:
a = policy(s)
s2, r, done = step(s, a)
# TD(0) 更新
V[s] += alpha * (r + gamma * V[s2] - V[s])
s = s2
return V
s_t = time.time()
V_mc = first_visit_mc()
t_cost_mc = time.time() - s_t
print(f"First-Visit MC 用时: {t_cost_mc:.2f} 秒")
# ---------- 打印结果 ----------
grid_mc = np.array([[V_mc[f"s{r*3+c+1}"] for c in range(3)] for r in range(3)])
df_mc = pd.DataFrame(grid_mc.round(3),
columns=["col1","col2","col3"],
index=["row1","row2","row3"])
print(df_mc)
s_t = time.time()
V_td0 = td0_value_prediction()
t_cost_td0 = time.time() - s_t
print(f"TD(0) 用时: {t_cost_td0:.2f} 秒")
grid_td0 = np.array([[V_td0[f"s{r*3+c+1}"] for c in range(3)] for r in range(3)])
df_td0 = pd.DataFrame(grid_td0.round(3),
columns=["col1","col2","col3"],
index=["row1","row2","row3"])
print(df_td0)
运行代码后,得到结果如下:
First-Visit MC 用时: 0.57 秒
col1 col2 col3
row1 -4.43 -2.149 -1.0
row2 -2.15 -1.000 0.0
row3 -1.00 0.000 0.0
TD(0) 用时: 0.47 秒
col1 col2 col3
row1 -4.110 -2.216 -1.0
row2 -2.182 -1.000 0.0
row3 -1.000 0.000 0.0
可以发现,时序差分估计和蒙特卡洛估计得到的状态价值函数
5.3 时序差分目标的推导
那么时序差分目标
会发现,在给定策略
代入到蒙特卡洛更新公式式(1)中,就得到了时序差分更新公式式(3)。
注意,式(7)中的等价近似是有条件的,需要满足在"期望"的环境下。具体来说,首先需保证策略是稳定的(通常指策略能够收敛,感兴趣的读者也可参考后面要讲的策略梯度方法中的平稳分布概念),其次需要足够的探索,产生足够多样的轨迹,尽可能覆盖所有的回报情况。然后在此基础上通过不断地迭代更新
换句话说,在保证策略收敛的前提下,使用时序差分方法时,最重要的是足够多次的迭代更新和足够的探索性,否则时序差分估计可能会一直不稳定,从而无法收敛到最优策略,这是在实际应用中需要特别注意的地方。
在策略收敛前,由于状态价值函数
5.4 n 步时序差分
式(7)中的时序差分目标
可以看出该等价近似式中,前半部分是从时间步
如式
因此,
5.5 动态规划、蒙特卡洛和时序差分的比较
回顾动态规划、蒙特卡洛和时序差分这三种算法,它们都是强化学习中比较重要的价值估计方法,并且各自有不同的特点和适用场景,具体比较如表 1 所示。
| 方法 | 依赖环境模型 | 更新时机 | 估计方式 | 优缺点 |
|---|---|---|---|---|
| 动态规划 | 需要 | 每个时间步 | 自举 | 优点:收敛速度快;缺点:有模型方法,需要完整的环境模型 |
| 蒙特卡洛方法 | 不需要 | 回合结束后 | 采样 | 优点:无偏估计,无模型方法,适用于未知环境;缺点:需要完整回合,高方差,收敛速度慢 |
| 时序差分方法 | 不需要 | 每个时间步 | 自举和采样结合 | 优点:无模型方法,适用于未知环境,更新及时高效,低方差;缺点:有偏估计,可能不稳定,依赖于探索策略 |
5.6 Sarsa 算法
5.6.1 时序差分估计动作价值
在讲解
5.6.2 Sarsa 算法流程
参考蒙特卡洛控制算法的流程,结合时序差分估计动作价值的方式,

可以看出,由于时序差分方法是在每个时间步进行更新的,因此
5.6.3 探索策略
前面讲到,为了保证时序差分估计的收敛性,最好进行足够的探索。在
具体来说,在每个时间步,智能体以概率
其中
5.7 Q-learning 算法
类似的,算法流程如图 3 所示,完整的代码实现可参考实战部分的内容。

对比
具体对比总结如表 2 所示。
| 策略类型 | 异策略 | 同策略 |
| 更新目标 | 最优动作的估计值 | 实际采取动作的估计值 |
| 收敛速度 | 较快 | 较慢 |
| 稳定性 | 更激进,可能不稳定 | 较为稳健 |
| 适用场景 | 对于需要快速收敛到最优策略的场景如游戏智能体 | 对于需要稳健学习的场景如自动驾驶等 |
5.8 同策略与异策略
同策略
以学习开车为例,如图 4 所示,同策略中,驾驶者按照当前学到的驾驶技巧进行驾驶,同时也在学习和改进这些技巧;而在异策略中,驾驶者心里一直想着最优的驾驶方式,但实际驾驶时可能会因为交通状况、路况等因素而采取不同的驾驶策略。换句话说,同策略就是在"学自己",而异策略则是在"看别人学或学理想中的自己"。
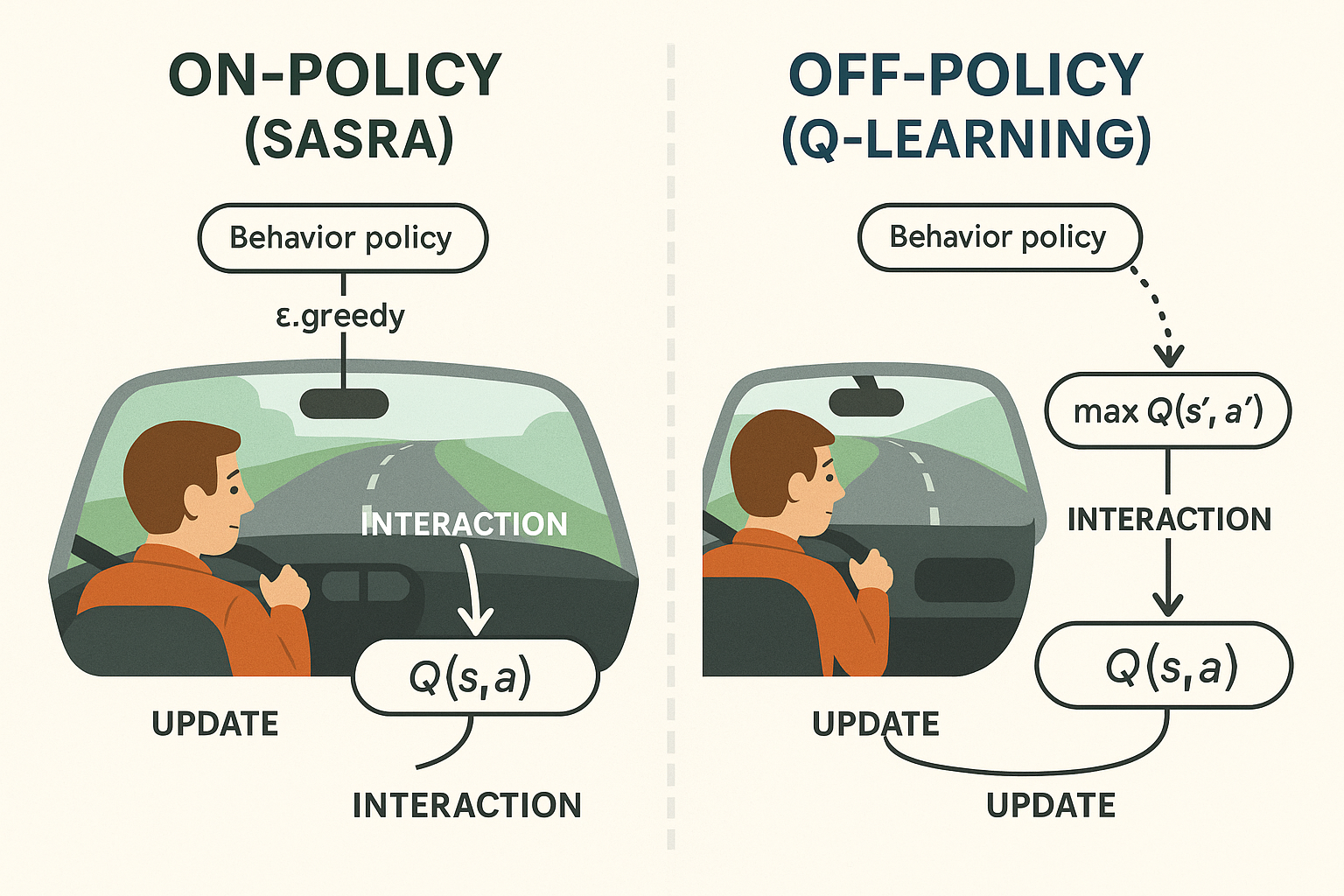
实际应用中,同策略方法通常更加稳健,因为它直接基于当前的行为策略进行学习,能够更好地适应环境的变化;而异策略方法则更具灵活性,能够利用不同的行为策略来探索环境,从而可能更快地找到最优策略,但也可能面临稳定性和收敛性的问题。
5.9 思考
蒙特卡洛和时序差分都是无模型方法吗?
是的,蒙特卡洛方法和时序差分方法都是无模型(
蒙特卡洛方法和时序差分方法的优劣势分别是什么?
蒙特卡洛方法优势:可以直接从经验中学习,不需要环境的转移概率;直接基于完整回报进行估计,在回合式任务中概念直观;在固定策略下,对完整回报的估计通常是无偏的。蒙特卡洛方法劣势:需要等到一条完整的轨迹结束才能更新价值函数,因此效率较低;方差通常较大;对于没有明显终止状态或回合很长的任务不够友好。时序差分优势:可以在交互过程中逐步更新价值函数,效率较高;既能用于回合式任务,也能用于持续任务;可以结合函数逼近方法使用,对于高维状态空间的问题有很好的应用。时序差分劣势:由于使用自举,估计通常带有一定偏差;更新过程对学习率、探索策略等设置较敏感,可能影响收敛速度和稳定性。总的来说,蒙特卡洛方法更适合从完整回合中直接学习回报,而时序差分方法更适合需要边交互边学习、并强调样本效率的场景。在实际应用中需要根据问题的特点和实际情况选择合适的方法。
什么是
为什么需要探索策略?
探索策略是强化学习中非常重要的一个概念,原因有:强化学习的目标是学习一个最优策略,但初始时我们并不知道最优策略,因此需要通过探索来发现更优的策略;在强化学习中,往往存在许多未知的状态和动作,如果智能体只采用已知的策略,那么它将无法探索到未知状态和动作,从而可能会错过更优的策略;探索策略可以帮助智能体避免陷入局部最优解,从而更有可能找到全局最优解。常用的探索策略包括