Actor-Critic Algorithms
While pure policy gradient algorithms (such as REINFORCE) solve the problems of continuous action spaces and stochastic policies, their high variance and low sample efficiency limit performance on complex tasks.
Embodied Intelligence Perspective: Actor-Critic is the common foundational framework for mainstream algorithms such as PPO, SAC, and TD3. Understanding the principles of Actor-Critic (especially GAE) is crucial for debugging and improving RL training in embodied intelligence.
Drawbacks of Pure Policy Gradient
The policy gradient objective function:
When
Actor-Critic Principle
Actor-Critic delegates value estimation to an independent Critic network, while the Actor focuses on policy optimization:
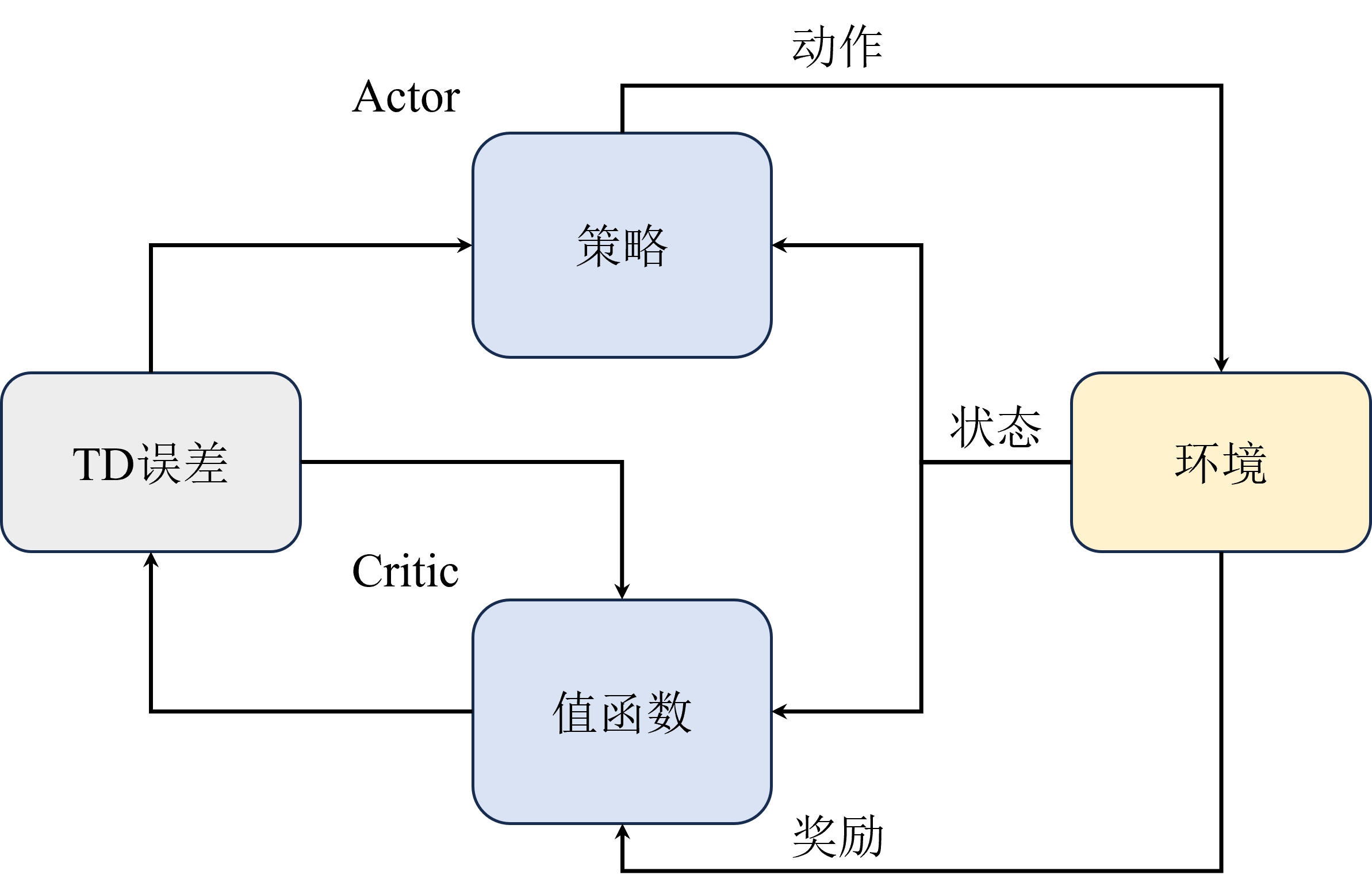
Actor-Critic is more of a framework — different algorithms may have different implementations. For the Critic component, either the state value function
Value Actor-Critic (using state value):
The Critic updates its parameters via temporal difference (TD) methods:
A2C Algorithm
To further reduce variance, the advantage function is introduced:
The advantage function measures how much better a specific action is compared to the average in a given state. By subtracting the baseline
A2C objective function:
A3C Algorithm
A3C (Asynchronous Advantage Actor-Critic) uses multiple parallel agents interacting with the environment simultaneously, with each agent asynchronously updating parameters to a global network:
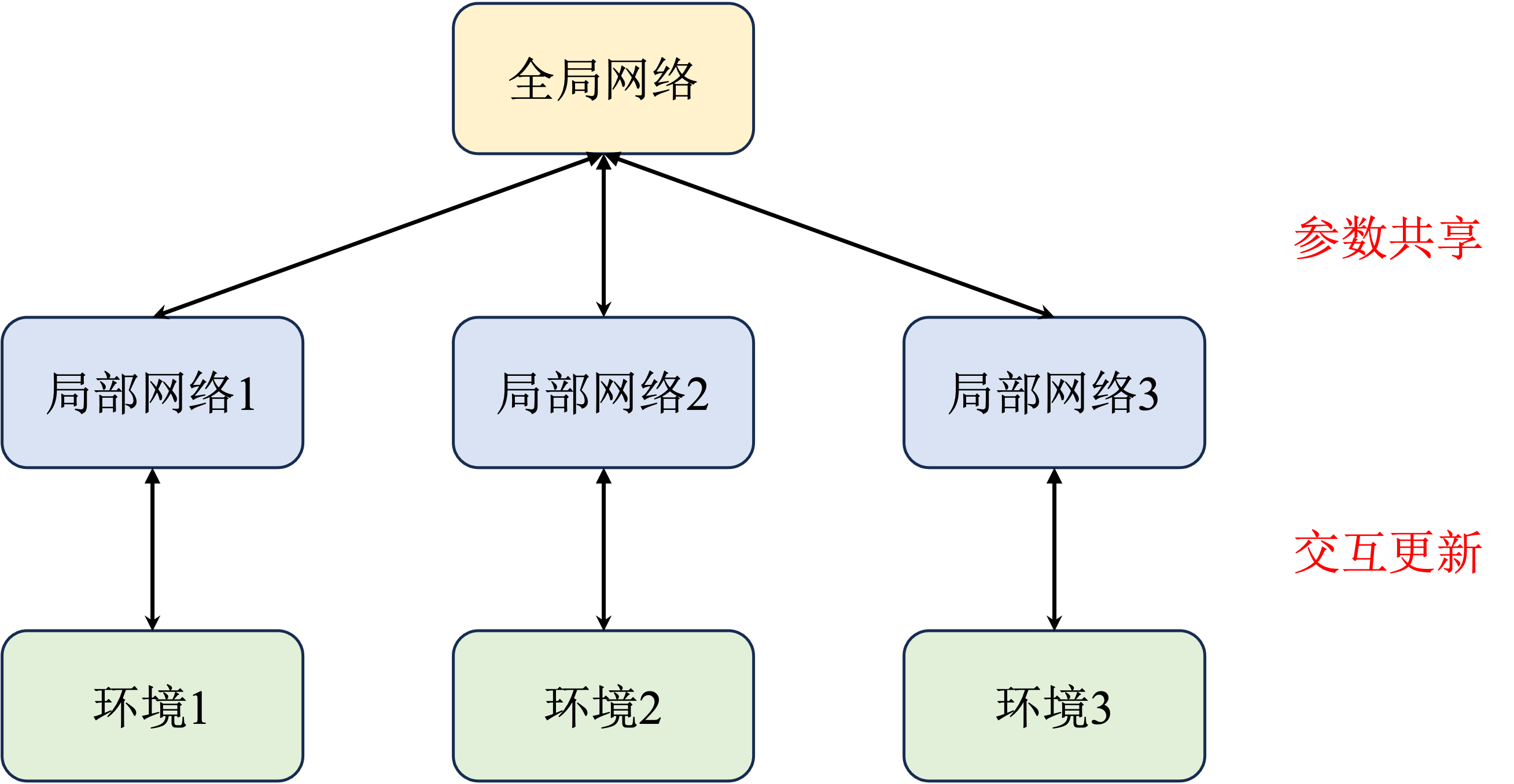
The multi-process training approach is also widely used in other algorithms (e.g., PPO in Isaac Gym uses thousands of parallel environments), significantly improving training efficiency and exploration capability.
Generalized Advantage Estimation (GAE)
The estimation method for the advantage function directly affects training performance. Common estimation methods include:
Single-step TD estimation (low variance, high bias):
Monte Carlo estimation (unbiased, high variance):
Generalized Advantage Estimation (GAE) balances between the two using parameter
where
GAE has an efficient recursive form that is very suitable for implementation:
- When
, it reduces to single-step TD error - When
, it reduces to Monte Carlo estimation - Typically
is used, balancing between bias and variance
GAE PyTorch Implementation
import torch
def compute_gae(rewards, values, dones, gamma=0.99, lam=0.95):
"""
Compute Generalized Advantage Estimation (GAE)
rewards: shape = [T], immediate reward at each step
values: shape = [T+1], value function V(s_t)
dones: shape = [T], whether the state is terminal
"""
T = len(rewards)
advantages = torch.zeros(T, dtype=torch.float32)
last_adv = 0.0
for t in reversed(range(T)):
if dones[t]:
next_non_terminal = 0.0
next_value = 0.0
else:
next_non_terminal = 1.0
next_value = values[t + 1]
delta = rewards[t] + gamma * next_value * next_non_terminal - values[t]
advantages[t] = delta + gamma * lam * next_non_terminal * last_adv
last_adv = advantages[t]
returns = advantages + values[:-1]
return advantages, returns
Summary
The Actor-Critic framework is the foundation of modern RL algorithms:
- Actor is responsible for policy optimization, Critic is responsible for value estimation
- Advantage function reduces variance by subtracting a baseline
- GAE provides a flexible bias-variance tradeoff
- PPO = Actor-Critic + importance sampling + clip constraint
- SAC = Actor-Critic + maximum entropy + automatic temperature tuning