4. 蒙特卡洛方法
蒙特卡洛方法的核心思想是通过大量的随机采样来近似估计期望或积分。在强化学习中,一方面可以用来解决预测问题,即估计状态价值函数
具身智能视角:蒙特卡洛方法是无模型强化学习的起点。在机器人学习中,当环境模型未知(如真实物理世界)时,我们只能通过与环境交互来收集经验数据。蒙特卡洛方法的"采样-估计"范式正是后续所有无模型 RL 算法的基础。
蒙特卡洛预测包括首次访问法和每次访问法两种基本方法,前者只在每个状态的首次访问时更新价值估计,后者则在每次访问时都进行更新。
蒙特卡洛控制则结合了蒙特卡洛预测和策略改进,通过采样来估计动作价值函数,并基于该估计来改进策略,最终实现策略的优化。
4.1 状态价值计算示例
为帮助理解蒙特卡洛方法,我们先举一个简单的例子来根据定义计算状态价值,然后再介绍蒙特卡洛预测算法。
如图 1 所示,考虑智能体在
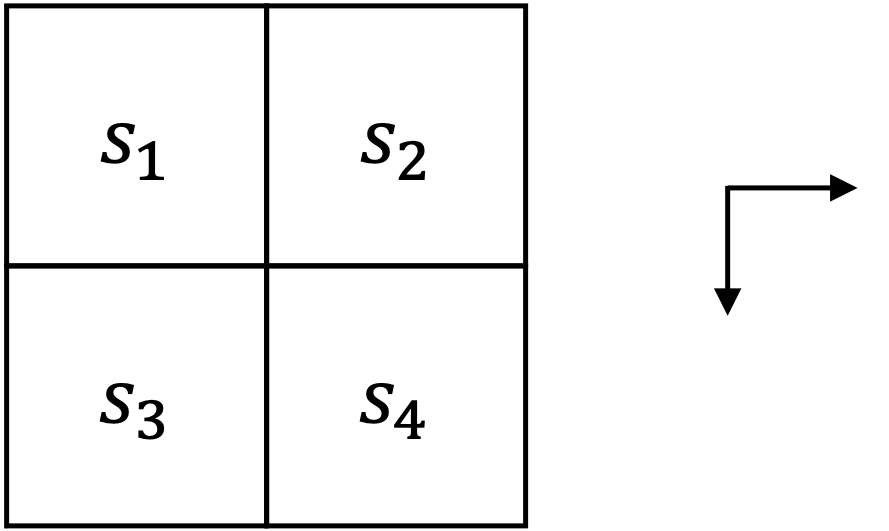
回顾状态价值函数的定义,如式
现在根据定义来分别计算各状态的价值,首先由于
接下来计算
然后计算
最后计算起始状态
相应地,对应的回报计算分别如式
由于智能体采用随机策略,因此两条轨迹的概率相等,均为
综上所述,各状态的价值函数结果如表 1 所示。
| 状态 | ||||
|---|---|---|---|---|
| 价值 |
下面将介绍蒙特卡洛方法是如何通过采样来估计状态价值的。
4.2 蒙特卡洛预测
4.2.1 蒙特卡洛估计
蒙特卡洛估计是一种用随机采样近似求期望、积分或概率分布特征的通用方法。换句话说,如果想求一个复杂的数学期望(或积分),而无法直接解析求解时,就可以用大量随机样本的平均值去逼近它。
假设我们想要估计某个函数
其中
- 从概率分布
中采样 个独立同分布的样本 。 - 计算函数值的平均,如式
所示。
根据大数定律,当样本数量
为帮助理解,我们来演示如何通过蒙特卡洛方法来估计圆周率
用 Python 代码实现这个过程,如代码 1 所示。
import random
def monte_carlo_pi(num_samples=1000000):
count_in_circle = 0
for _ in range(num_samples):
x, y = random.random(), random.random()
if x**2 + y**2 <= 1:
count_in_circle += 1
pi_estimate = 4 * count_in_circle / num_samples
return pi_estimate
print("Estimated π:", monte_carlo_pi())
运行代码后,可以得到一个接近
蒙特卡洛预测(
4.2.2 增量式更新
在实际应用中,由于状态空间可能非常大,估计状态价值所需的轨迹数量可能上万甚至更多。一方面,轨迹是通过智能体与环境交互产生的,这一交互过程可能也会非常耗时;另一方面,存储和处理大量轨迹数据也会带来计算和内存的压力。
为了解决这些问题,蒙特卡洛预测通常采用增量式更新的方式来估计状态价值,即边采样边更新,而不是等采样完所有轨迹后再进行批量更新。
如式
其中
其中
可以发现,增量式更新的核心思想如式
4.2.3 首次访问蒙特卡洛
在增量式更新的基础上,蒙特卡洛方法主要分成两种算法,一种是首次访问蒙特卡洛(
我们先来看首次访问蒙特卡洛(

假设我们已经采样得到了一条完整的轨迹
回头看我们前面的示例,可以用
import numpy as np
from collections import defaultdict
# ----------- 环境定义 -----------
states = ['s1', 's2', 's3', 's4']
gamma = 0.9
R = -1
terminal = 's4'
# 状态转移(确定性)
transitions = {
's1': {'right': 's2', 'down': 's3'},
's2': {'down': 's4'},
's3': {'right': 's4'},
}
# 策略 π:在合法动作间随机选择
def policy(state):
actions = list(transitions[state].keys())
return np.random.choice(actions)
# 生成一条完整轨迹(从 s1 到 s4)
def generate_episode():
episode = []
state = 's1'
while state != terminal:
action = policy(state)
next_state = transitions[state][action]
episode.append((state, action, R))
state = next_state
episode.append((terminal, None, 0)) # 终止
return episode
def first_visit_mc(num_episodes=1000):
V = defaultdict(float)
returns = defaultdict(list)
for _ in range(num_episodes):
episode = generate_episode()
G = 0
visited = set() # 用于记录首访
# 反向遍历轨迹
for state, action, reward in reversed(episode):
G = gamma * G + reward
if state not in visited:
visited.add(state)
returns[state].append(G)
V[state] = np.mean(returns[state])
return V
if __name__ == "__main__":
V_first = first_visit_mc()
print("First-Visit MC:")
for s in states:
print(f" {s}: {V_first[s]:.2f}")
运行结果如下:
First-Visit MC:
s1: -1.90
s2: -1.00
s3: -1.00
s4: 0.00
可以发现,估计的状态价值函数与我们前面根据定义计算的结果是一致的。
注意,只在第一次遍历到某个状态时会记录并计算对应的回报,对应伪代码如图 2 所示。
4.2.4 每次访问蒙特卡洛
在
import numpy as np
from collections import defaultdict
# ----------- 环境定义 -----------
states = ['s1', 's2', 's3', 's4']
gamma = 0.9
R = -1
terminal = 's4'
# 状态转移(确定性)
transitions = {
's1': {'right': 's2', 'down': 's3'},
's2': {'down': 's4'},
's3': {'right': 's4'},
}
# 策略 π:在合法动作间随机选择
def policy(state):
actions = list(transitions[state].keys())
return np.random.choice(actions)
# 生成一条完整轨迹(从 s1 到 s4)
def generate_episode():
episode = []
state = 's1'
while state != terminal:
action = policy(state)
next_state = transitions[state][action]
episode.append((state, action, R))
state = next_state
episode.append((terminal, None, 0)) # 终止
return episode
def every_visit_mc(num_episodes=1000):
V = defaultdict(float)
returns = defaultdict(list)
for _ in range(num_episodes):
episode = generate_episode()
G = 0
# 反向遍历轨迹(每次出现都更新)
for state, action, reward in reversed(episode):
G = gamma * G + reward
returns[state].append(G)
V[state] = np.mean(returns[state])
return V
if __name__ == "__main__":
V_every = every_visit_mc()
print("\nEvery-Visit MC:")
for s in states:
print(f" {s}: {V_every[s]:.2f}")
同样运行结果如下:
Every-Visit MC:
s1: -1.90
s2: -1.00
s3: -1.00
s4: 0.00
总的来说,
4.3 蒙特卡洛估计动作价值
蒙特卡洛预测或者估计动作价值函数
-
生成完整轨迹:与状态价值函数相同,首先需要通过与环境的交互生成一条完整的轨迹,包括状态、动作和奖励。
-
计算回报:对于轨迹中的每个状态-动作对
,计算从该对开始的回报 。 -
更新价值函数:根据计算得到的回报更新动作价值函数
,可以使用首次访问或每次访问的方式。 具体的增量式更新公式与状态价值函数类似,如式 所示。
其中
使用Python 代码实现蒙特卡洛动作价值估计来解决前面示例的问题,如代码 6 所示。
import numpy as np
from collections import defaultdict
states = ['s1', 's2', 's3', 's4']
actions = ['right', 'down']
gamma = 0.9
R = -1
terminal = 's4'
# 转移定义
transitions = {
('s1', 'right'): 's2',
('s1', 'down'): 's3',
('s2', 'down'): 's4',
('s3', 'right'): 's4',
}
def policy(state):
# 随机策略 π(a|s)
legal = [a for (s,a) in transitions if s == state]
return np.random.choice(legal)
def generate_episode():
episode = []
state = 's1'
while state != terminal:
action = policy(state)
next_state = transitions[(state, action)]
episode.append((state, action, R))
state = next_state
episode.append((terminal, None, 0))
return episode
def mc_action_value(num_episodes=1000):
Q = defaultdict(float)
returns = defaultdict(list)
for _ in range(num_episodes):
episode = generate_episode()
G = 0
visited = set()
for state, action, reward in reversed(episode):
G = gamma * G + reward
if action is not None and (state, action) not in visited:
visited.add((state, action))
returns[(state, action)].append(G)
Q[(state, action)] = np.mean(returns[(state, action)])
return Q
Q = mc_action_value()
for (s,a), v in Q.items():
print(f"Q({s},{a}) = {v:.2f}")
运行结果如下:
Q(s1,down) = -1.90
Q(s1,right) = -1.90
Q(s2,down) = -1.00
Q(s3,right) = -1.00
联系状态价值和动作价值的关系,如式
以状态
可以发现,计算结果与前面直接估计的状态价值是一致的。
4.4 蒙特卡洛控制
4.4.1 更复杂的蒙特卡洛预测示例
为了更好地理解蒙特卡洛控制方法,先举一个稍微更复杂的蒙特卡洛预测示例(虽然并没有复杂多少,因为状态空间上仍然较小)。
如图 3 所示,在前面
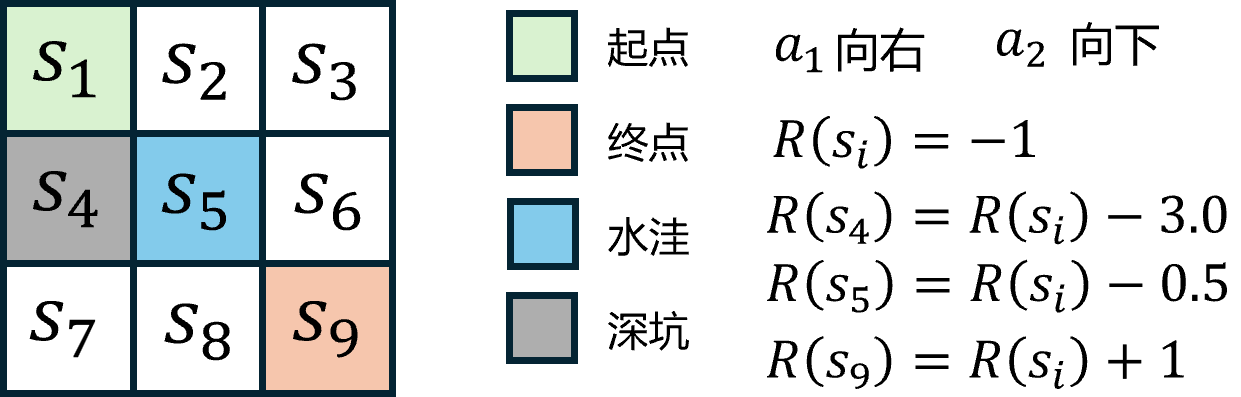
除了每走一步接收
用 Python 代码实现蒙特卡洛方法来估计状态价值函数,如代码 8 所示。
import random
from collections import defaultdict
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# ---------- 参数 ----------
gamma = 0.9
episodes = 30000
states = [f"s{i}" for i in range(1, 10)]
terminal = "s9"
start = "s1"
coords = {
"s1": (0,0), "s2": (0,1), "s3": (0,2),
"s4": (1,0), "s5": (1,1), "s6": (1,2),
"s7": (2,0), "s8": (2,1), "s9": (2,2)
}
# ---------- 环境 ----------
def legal_actions(s):
r, c = coords[s]
acts = []
if c < 2: acts.append("right")
if r < 2: acts.append("down")
return acts
def step(s, a):
r, c = coords[s]
if a == "right": r2, c2 = r, c + 1
elif a == "down": r2, c2 = r + 1, c
s2 = [k for k, v in coords.items() if v == (r2, c2)][0]
reward = -1.0
# 额外惩罚修改 ↓↓↓
if s2 == "s4": reward -= 3.0 # 深坑
if s2 == "s5": reward -= 0.5 # 水洼
if s2 == "s9": reward += 1.0 # 终点 +1 → 净0
done = (s2 == terminal)
return s2, reward, done
def policy(s):
acts = legal_actions(s)
return random.choice(acts)
def generate_episode():
episode = []
s = start
while True:
if s == terminal:
episode.append((s, None, 0))
break
a = policy(s)
s2, r, done = step(s, a)
episode.append((s, a, r))
s = s2
return episode
# ---------- First-Visit Monte Carlo ----------
def first_visit_mc(num_episodes=episodes, gamma=0.9):
V = defaultdict(float)
N = defaultdict(int)
for _ in range(num_episodes):
episode = generate_episode()
G = 0
visited = set()
for s, a, r in reversed(episode):
G = gamma * G + r
if s not in visited:
visited.add(s)
N[s] += 1
V[s] += (G - V[s]) / N[s]
return V
V = first_visit_mc()
# ---------- 打印结果 ----------
grid = np.array([[V[f"s{r*3+c+1}"] for c in range(3)] for r in range(3)])
df = pd.DataFrame(grid.round(3),
columns=["col1","col2","col3"],
index=["row1","row2","row3"])
print(df)
# ---------- 热力图展示 ----------
plt.figure(figsize=(5,5))
plt.imshow(grid, cmap='coolwarm', origin='upper')
for i in range(3):
for j in range(3):
plt.text(j, i, f"{grid[i,j]:.2f}", ha='center', va='center', color='black')
plt.title("Monte Carlo State Values")
plt.colorbar(label="V(s)")
plt.tight_layout()
plt.show()
执行代码后,除了打印出各状态的价值函数结果外,还会生成一个热力图来直观展示各状态的价值分布情况,如图 4 所示。
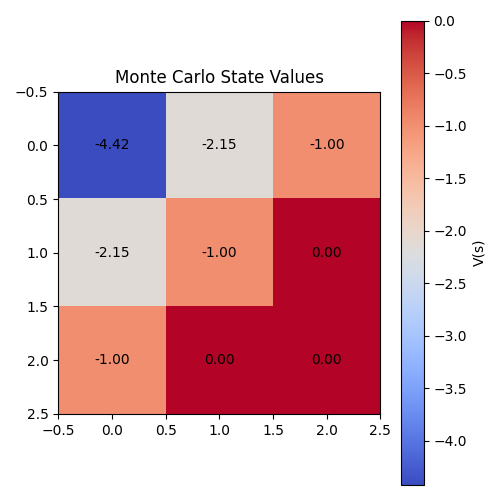
初学者可能会有疑问,为什么平地状态例如
由于智能体采用的是随机策略,且动作只能向右或向下移动,因此从起始状态
而对于障碍物位置
同样地,可以用蒙特卡洛方法来估计动作价值函数
import random
from collections import defaultdict
import numpy as np
import matplotlib.pyplot as plt
# ---------- 参数 ----------
gamma = 0.9
episodes = 30000
states = [f"s{i}" for i in range(1, 10)]
terminal = "s9"
start = "s1"
coords = {
"s1": (0,0), "s2": (0,1), "s3": (0,2),
"s4": (1,0), "s5": (1,1), "s6": (1,2),
"s7": (2,0), "s8": (2,1), "s9": (2,2)
}
# ---------- 环境 ----------
def legal_actions(s):
r, c = coords[s]
acts = []
if c < 2: acts.append("right")
if r < 2: acts.append("down")
return acts
def step(s, a):
r, c = coords[s]
if a == "right": r2, c2 = r, c + 1
elif a == "down": r2, c2 = r + 1, c
s2 = [k for k, v in coords.items() if v == (r2, c2)][0]
reward = -1.0
if s2 == "s4": reward -= 3.0 # 深坑
if s2 == "s5": reward -= 0.5 # 水洼
if s2 == "s9": reward += 1.0 # 终点奖励 +1 → 净0
done = (s2 == terminal)
return s2, reward, done
def policy(s):
acts = legal_actions(s)
return random.choice(acts)
def generate_episode():
episode = []
s = start
while True:
if s == terminal:
episode.append((s, None, 0))
break
a = policy(s)
s2, r, done = step(s, a)
episode.append((s, a, r))
s = s2
return episode
def first_visit_mc_Q(num_episodes=episodes, gamma=0.9):
Q = defaultdict(float)
N = defaultdict(int)
for _ in range(num_episodes):
episode = generate_episode()
G = 0
visited = set()
for s, a, r in reversed(episode):
G = gamma * G + r
if a is None:
continue
if (s, a) not in visited:
visited.add((s, a))
N[(s, a)] += 1
Q[(s, a)] += (G - Q[(s, a)]) / N[(s, a)]
return Q
Q = first_visit_mc_Q()
# 构建Q值矩阵
q_right = np.full((3, 3), np.nan)
q_down = np.full((3, 3), np.nan)
for s in states:
if "right" in legal_actions(s):
r, c = coords[s]
q_right[r, c] = Q[(s, "right")]
if "down" in legal_actions(s):
r, c = coords[s]
q_down[r, c] = Q[(s, "down")]
for r in range(3):
for c in range(3):
s = [k for k, v in coords.items() if v == (r, c)][0]
print(f"State {s}: Q(s, 'right') = {q_right[r,c]:.2f}, Q(s, 'down') = {q_down[r,c]:.2f}")
# 可视化 Q(s,a) 热力图
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
im1 = axes[0].imshow(q_right, cmap='coolwarm', origin='upper')
axes[0].set_title("Q(s1, a='right')")
for i in range(3):
for j in range(3):
if not np.isnan(q_right[i, j]):
axes[0].text(j, i, f"{q_right[i,j]:.2f}", ha='center', va='center', color='black')
fig.colorbar(im1, ax=axes[0])
im2 = axes[1].imshow(q_down, cmap='coolwarm', origin='upper')
axes[1].set_title("Q(s1, a='down')")
for i in range(3):
for j in range(3):
if not np.isnan(q_down[i, j]):
axes[1].text(j, i, f"{q_down[i,j]:.2f}", ha='center', va='center', color='black')
fig.colorbar(im2, ax=axes[1])
plt.suptitle("Monte Carlo Action Values")
plt.tight_layout()
plt.show()
执行代码后,可以得到各状态-动作对的动作价值函数结果,并生成两个热力图来直观展示各状态在不同动作下的价值分布情况,如图 5 所示。
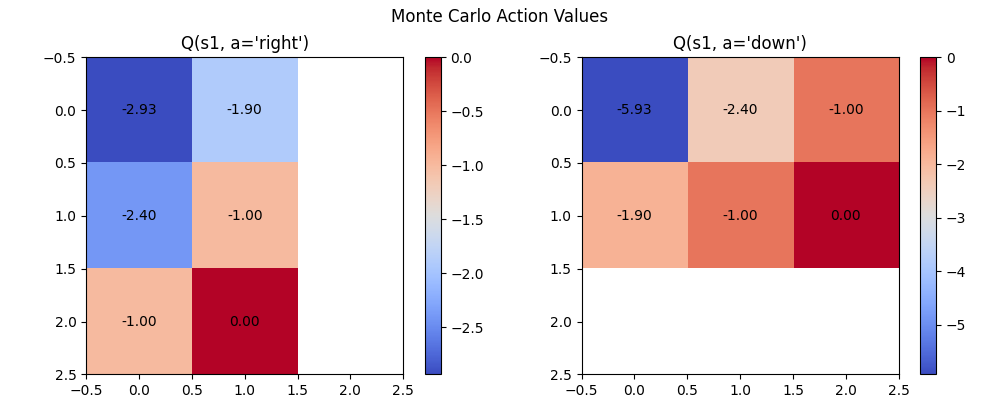
可以发现,从状态
4.4.2 蒙特卡洛控制算法
在计算动作价值的过程中,可以借鉴动态规划中策略迭代的思想,先进行策略评估,即预测动作价值,然后基于当前的动作价值函数进行策略改进,形成一个新的策略,如式
这种利用蒙特卡洛方法交替进行策略评估和策略改进的过程,称为蒙特卡洛控制(

在
import random
from collections import defaultdict
import numpy as np
import matplotlib.pyplot as plt
# ---------- 环境定义 ----------
gamma = 0.9
states = [f"s{i}" for i in range(1, 10)]
terminal = "s9"
coords = {
"s1": (0,0), "s2": (0,1), "s3": (0,2),
"s4": (1,0), "s5": (1,1), "s6": (1,2),
"s7": (2,0), "s8": (2,1), "s9": (2,2)
}
def legal_actions(s):
r, c = coords[s]
acts = []
if c < 2: acts.append("right")
if r < 2: acts.append("down")
return acts
def step(s, a):
r, c = coords[s]
if a == "right": r2, c2 = r, c + 1
elif a == "down": r2, c2 = r + 1, c
s2 = [k for k, v in coords.items() if v == (r2, c2)][0]
reward = -1.0
if s2 == "s4": reward -= 3.0
if s2 == "s5": reward -= 0.5
if s2 == "s9": reward += 1.0
done = (s2 == terminal)
return s2, reward, done
# ---------- Monte Carlo ES 控制 ----------
def monte_carlo_es(num_episodes=10000, gamma=0.9):
Q = defaultdict(float)
Returns = defaultdict(list)
policy = {}
# 初始化策略 π 随机
for s in states:
actions = legal_actions(s)
if actions:
policy[s] = random.choice(actions)
for episode in range(num_episodes):
# Exploring Starts: 随机选起点 (s0, a0)
s0 = random.choice([s for s in states if s != terminal])
actions = legal_actions(s0)
if not actions:
continue
a0 = random.choice(actions)
# 生成一条完整轨迹
episode_list = []
s, a = s0, a0
while True:
s_next, r, done = step(s, a)
episode_list.append((s, a, r))
if done:
break
a = policy.get(s_next, random.choice(legal_actions(s_next)))
s = s_next
# 反向计算 G 并更新 Q
G = 0
visited = set()
for s, a, r in reversed(episode_list):
G = gamma * G + r
if (s, a) not in visited:
visited.add((s, a))
Returns[(s,a)].append(G)
Q[(s,a)] = np.mean(Returns[(s,a)])
# 策略改进:贪婪选择
policy[s] = max(legal_actions(s), key=lambda x: Q[(s,x)])
return policy, Q
policy, Q = monte_carlo_es()
# ---------- 输出结果 ----------
print("最优策略 π(s):")
for s in states:
if s in policy:
print(f"{s}: {policy[s]}")
print("\n示例部分 Q 值:")
for k in list(Q.keys())[:10]:
print(k, "=", round(Q[k], 2))
执行代码后,可以得到最优策略
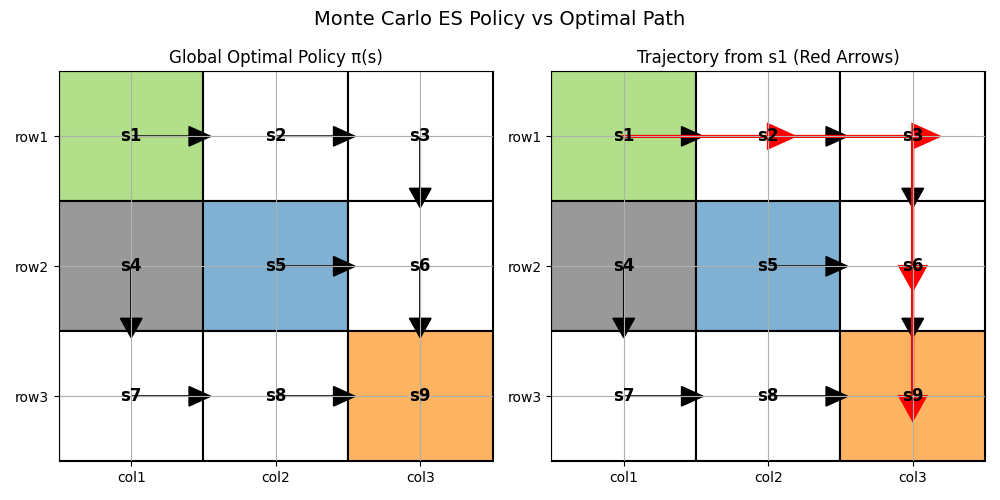
左图展示了不同状态下的全局最优策略,右图用红色箭头高亮显示了从起始状态
可以看到,智能体在最优路径上避开了障碍物