Policy Gradient Methods
Policy gradient methods are the most commonly used family of RL methods in embodied intelligence (PPO, SAC, etc. all belong to this family). The core idea is to directly parameterize the policy and then improve it through gradient optimization.
Embodied Intelligence Perspective: Robot control typically involves high-dimensional continuous action spaces (e.g., 30+ degrees of freedom for a humanoid robot). Policy gradient methods can directly output continuous joint torques without discretizing the action space, making them the core method for embodied intelligence.
Policy Parameterization
Policy gradient methods first parameterize the policy, i.e., directly parameterize
The objective function is denoted as
In practice, this is often converted to gradient descent (minimizing the negative):
Trajectory Probability Density
The agent interacts with the environment to produce trajectories:
The probability of generating a trajectory:
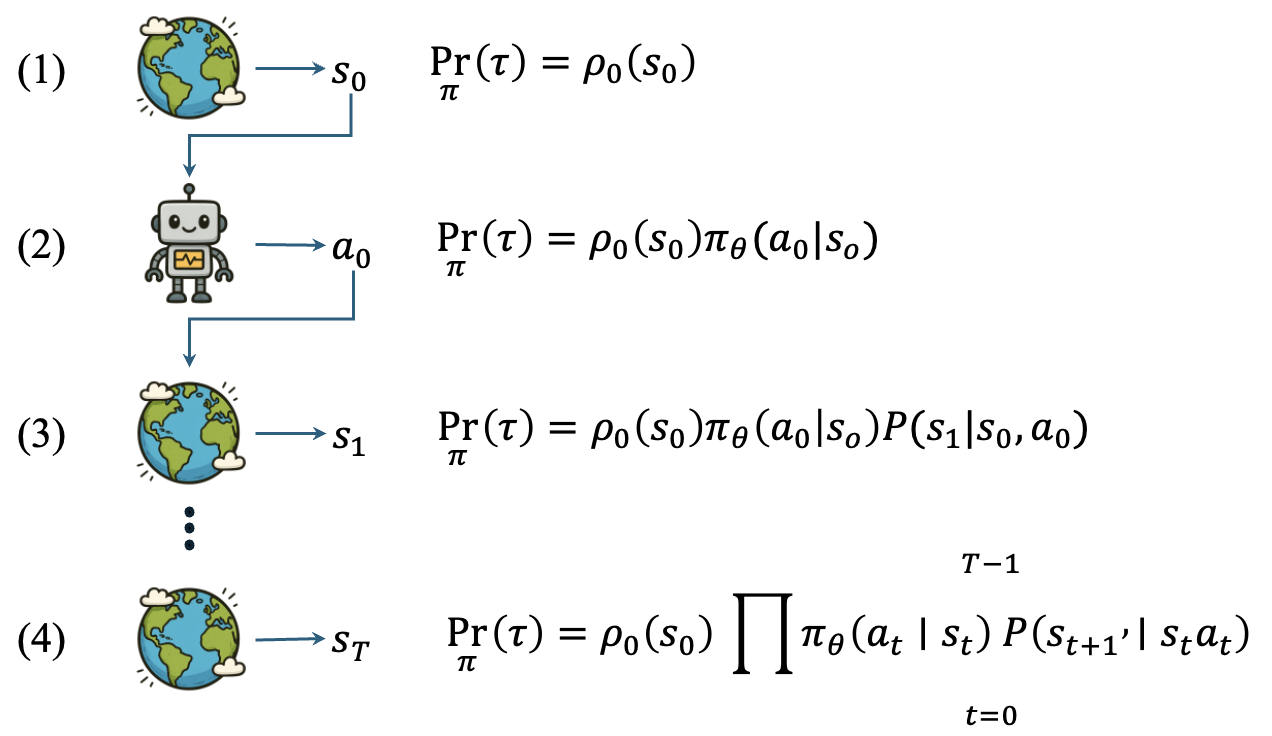
The objective function is the expected trajectory return:
Policy Gradient Theorem
Using the log-derivative trick (
where
Policy Function Modeling
Discrete Action Space: Categorical Distribution
For discrete action spaces, the Softmax function converts network outputs into a probability distribution:
Continuous Action Space: Gaussian Distribution
For continuous action spaces (the common scenario in robot control), a Gaussian distribution is used to parameterize the policy:
where the mean
For multi-dimensional action spaces (e.g., multi-joint robots), a multivariate Gaussian distribution with independent dimensions is used:
REINFORCE Algorithm
REINFORCE is the most basic policy gradient algorithm, using Monte Carlo estimation to compute the return

REINFORCE is simple and intuitive but suffers from high variance and low sample efficiency, since it requires complete trajectories to estimate returns. This is precisely the problem that Actor-Critic algorithms aim to solve.
Summary
Policy gradient methods lay the theoretical foundation for advanced algorithms (Actor-Critic, PPO, SAC). Key takeaways:
- The policy is parameterized as a differentiable probability distribution
- The log-derivative trick makes gradient computation independent of the environment model
- Gaussian policies are the standard choice for continuous control
- The high variance of REINFORCE motivated the development of the Actor-Critic framework